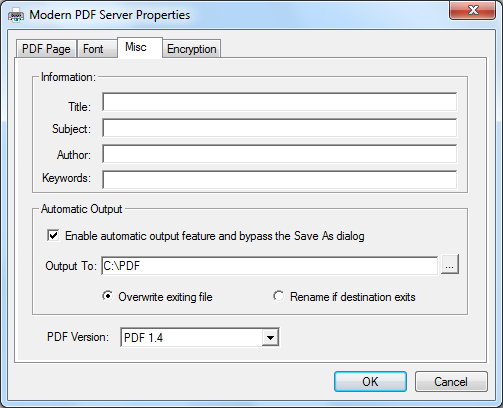
Document Properties |
Misc Tab
With the massive volume of documents being produced every day, creators spend much of their time perfecting content and layout. Far too often, authors ignore the finishing touch, the addition of metadata - an essential collection of information that helps make a document's unique content stand out in the crowd.
The inclusion of metadata can enable your documents with the proper identity so that users can find essential information quickly. When used with a search tool, these documents become part of an index that makes searching large numbers of PDF files fast and efficient.
You will see a number of default metadata options in a PDF document, none of which are populated by Microsoft Office applications other than Title, Subject, Author and Keywords. You can delete these placeholders if needed, but since there is no data there, it should not be a concern.
Metadata is hidden information in a computer file that may contain potentially dangerous or embarrassing information or lead to an accidental disclosure. In Office documents, there are many instances of data hidden in files, such as Word's Track Changes, that have been highly publicized.
For the most part, PDF is immune to these issues. PDFs represent the visual display as it will be printed. Still, it is a good idea to understand what if any risks are associated with PDF and metadata.
So, modernistically, here is what firms should be concerned about before sending out a PDF:
1. Are the Title, Subject, Author and Keyword fields empty?
Can be performed manually via Document Properties-->Description or in batch in Acrobat Reader.
2. Are there annotations on the document?
Can be deleted using the Comments tab in Document Properties.